.svg)
.webp)
Building an API with Django and Celery
Now, when we’ve already built our machine learning model, the first thing we need to do is to add all necessary applications and libraries to our requirements:
celery==4.2.0
django-cors-headers==2.4.0
django>=2.1,<2.2
djangorestframework==3.8.2
django-redis==4.9.0
psycopg2==2.7.5
django-environ==0.4.5
colour==0.1.5
pillow==5.3.0
nltk==3.4
numpy==1.15.4
matplotlib==3.0.2
pandas==0.23.4
scipy==1.1.0
requests==2.19.1
redis==2.10.6
scikit-learn==0.20.0
stemming==1.0.1
progressbar2==3.38.0
uwsgi==2.0.17.1
Then we create a Django project, an app called api and we put our hate_speech_AI inside this project (remember to add a __init__.py to the hate_speech_AI folder so django can see it) and we configure Docker to make it work. This is how your whole project should look like.
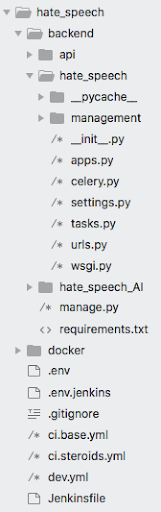
In the Docker file, you have to put all necessary things to create the Django image and the dev.yml will be your docker compose file. We are going to skip all the Django configuration as you can check the hate speech detector’s code in the public repo. Just remember to add to your docker-compose celery, celerybeat and a bootstrap service. It will be run every time the project is set up and we are going to need that.
At this point, we will focus on the app called api allowing us to serve a REST API to use our classifier. We will also learn how to create and train the model once the project has been run so it is ready for further use. Finally, we will see how celery can help us with these tasks.
We want the application to run the train model at the start so it will be ready to predict. In this case, the training is necessary every time we build up the project again. We are doing it automatically, but you can also create an endpoint to do so, then every time you want to retrain the model, you just have to enter that endpoint. We are going to create a celery task that simply runs the train_model method of the classifier. I will skip the celery configuration since it is not the topic of this article.
from celery import shared_task
from hate_speech_AI.core import classifier
@shared_task
def auto_first_train_model():
classifier.train_model()
print('Model trained')
As you can see we are just importing the model and running the train_model method. The method will do the rest as we prepared the model for every scenario (train the model, dump it and the vectorizer, set the score in cache).
Of course, we need to run this task as the project is set up, so we are going to create a django command that will be run by our bootstrap service as the container is up.
from django.core.management.base import BaseCommand
from hate_speech.tasks import auto_first_train_model
class Command(BaseCommand):
help = 'Runs first training'
def handle(self, *args, **options):
auto_first_train_model.delay()
We named the file containing this command: exec_train.py so in our docker compose we just need to call it as a python manage.py command:
train:
image: hate_speech_django
command: python manage.py exec_train
deploy:
restart_policy:
condition: on-failure
depends_on:
- redis
Views and serializers
We are going to create a simple serializer with only one CharField. It will take care of the validation that the POSTed information is a valid string.
The view that uses this serializer will be the one used for prediction:
class PredictHateSpeechView(GenericAPIView):
serializer_class = TweetInputSerializer
permissions = [AllowAny]
def post(self, request):
serializer = self.get_serializer(data=request.data)
if serializer.is_valid():
tweet = serializer.data.get('tweet')
tweet = clean_and_tokenize_string(tweet)
prediction = classifier.predict_single_tweet(tweet)
return Response(
{'is_hate_speech': bool(prediction)},
status=status.HTTP_200_OK,
)
return Response(
{'errors': serializer.errors},
status=status.HTTP_400_BAD_REQUEST,
)
def clean_and_tokenize_string(tweet):
assert type(tweet) == str
tweet = remove_pattern(tweet, "@[\w]*")
tweet = tweet.replace("[^a-zA-Z#]", " ")
tweet = ' '.join([w for w in tweet.split() if len(w) > 3])
tokenized_tweet = tweet.split()
tokenized_tweet = [stem(i) for i in tokenized_tweet]
tokenized_tweet = ' '.join(tokenized_tweet)
return tokenized_tweet
The view is pretty self-explanatory. We take the post that the user introduced, clean and tokenize it with a function similar to the one used for the tweets and run the classifier with the method described earlier to get predictions. As the result is 0 or 1, we just have to bool it to return true or false, which is more pythonic.
A second serializer will be very similar to the previous one, but we are going to add a new field to mark if some text is a hate speech or not:
class ReviewedTweetInputSerializer(serializers.Serializer):
tweet = serializers.CharField(required=True)
is_hate_speech = serializers.BooleanField(required=True)
class Meta:
fields = ('tweet', 'is_hate_speech',)
Our idea is to create an endpoint where you can manually add your reviewed tweets and add them to the current CSV file of tweets.
class AddReviewedTweetManuallyView(GenericAPIView):
serializer_class = ReviewedTweetInputSerializer
permissions = [AllowAny]
def post(self, request):
serializer = self.get_serializer(data=request.data)
if serializer.is_valid():
train_file = pd.read_csv('/code/hate_speech_AI/train.csv')
tweet = serializer.data.get('tweet')
is_hate_speech = serializer.data.get('is_hate_speech')
label = 1 if is_hate_speech else 0
id = len(train_file) + 1
data_to_append = pd.DataFrame(
[[id, label, tweet]],
columns=['id', 'label', 'tweet'],
)
with open('/code/hate_speech_AI/train.csv', 'a') as f:
data_to_append.to_csv(f, header=False, index=False)
return Response(
{'detail': 'Tweet added to the database correctly'},
status=status.HTTP_200_OK,
)
return Response(
{'errors': serializer.errors},
status=status.HTTP_400_BAD_REQUEST,
)
As you can see, the serializer takes care for the validation and the view does the rest of the job. Now, on POST we will check the tweet and its label (is_hate_speech: True or False). Then we are going to read how many tweets we’ve already got and count them so the next id will be the amount of current tweets + 1. Then we prepare a Pandas DataFrame with the columns that already exist in the CSV file. Finally, we open the file in ‘a’ mode (it's reserved for append), pass the dataframe to CSV and append it to the already existing file. We mark header and index as false since we have already those declared before (columns and id).
This view will help us to explain how to use new tweets in our model. The Logistic Regression model has no extra training so once you trained it, you can only do it again. We are going to perform this part at night for a couple of days using the same file. We can enlarge it by adding tweets manually so the accuracy should increase with every train if the new tweets are correct. To do so we will use celery beat. As we’ve already got a task that trains the model the only thing we have to do is to create a schedule in our settings that runs it every day.
# --- CELERY ---
CELERY_BROKER_URL = env('CELERY_BROKER_URL', default='redis://redis:6379/')
CELERY_TIMEZONE = 'Europe/Warsaw'
CELERY_BEAT_SCHEDULE = {
'auto_first_train_model': {
'task': 'hate_speech.tasks.auto_first_train_model',
'schedule': crontab(hour=1),
'relative': True,
},
}
This task will operate every day at 1:00 AM, Warsaw time (UTC+1 hour).
Finally, we’ve got our simplest view for checking the score. Supposedly, with an increase of correctly labeled tweets, this score should raise after every train.
class GetScoreView(APIView):
permissions = [AllowAny]
def get(self, request):
score = classifier.get_score()
return Response({'score': score}, status=status.HTTP_200_OK)
As you can see, it is very simple as we’ve already implemented everything in our classifier object. We just call the get_score() method and the rest was explained in the Machine Learning section. Then just return the value returned.
And that would be all. Now we have an API that will return a prediction about a tweet if it is hate speech or not. We will also be able to feed the database that trains the model and check the score of it at the moment.
What’s next?
Of course, this ML model and the API can be improved. Those are the few ideas of how to do it:
- using the model enabling extra training;
- changing the vectorizer;
- use Tensorflow which is a very advanced framework for machine learning;
- create a scrapper or an importer to keep feeding the database(actually, the data provided in this article combine 2 different databases I found in 2 repositories that have a similar scope).
Did you like this project? Join our backend team and do awesome coding with us! We’re looking for software developers - check our job offers!



Navigate the changing IT landscape
Some highlighted content that we want to draw attention to to link to our other resources. It usually contains a link .
.svg)
.svg)
.svg)
.avif)

.avif)
.avif)
.avif)