.svg)
.webp)
And if you, by any chance, missed Part 1, in which I introduce the idea behind the project, the tech stack I decided on, and show you the evolution of the code – go read it immediately! For now, however, let’s go back to our app.
Project dockerization
Dockerfile has a simple structure and the only optimization made during the development was choosing “slim” version of Debian’s image.
FROM python:3.8-slim-buster
WORKDIR /app
COPY requirements.txt /app/requirements.txt
COPY dev-requirements.txt /app/dev-requirements.txt
COPY setup.cfg /app/setup.cfg
RUN pip install -r dev-requirements.txt
COPY src/ /app/src/
CMD ["python", "src/main.py"]
I have two separate docker-compose files: one for development and one for production. The development one consists of two services, web and database. In the production version, there is no database added since it’s handled by AWS’ RDS and it has Nginx running as a reverse proxy.
Moving the database to another server allowed me to save up some precious gigabytes of disk space at the cost of slightly higher (no more than 10-20ms) response times. This config means that I have de facto twice that much RAM and CPUs available and I do not have to worry about regular backups.
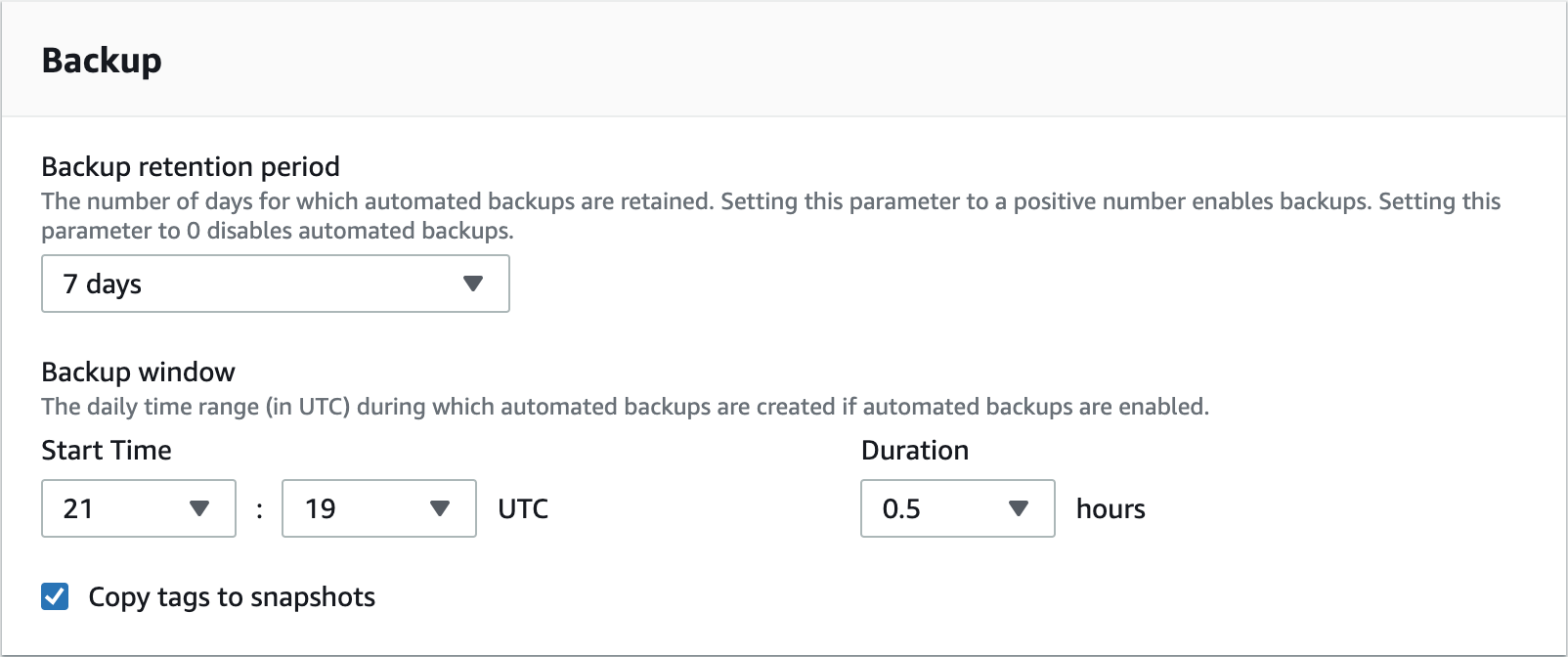
The only thing that I found troublesome was opening the database to a public network to be able to access it with PgAdmin or PyCharm’s database manager. Not only did I need to set up proper security groups, but also explicitly mark the option to expose database.

What’s more, there are Newrelic tools used. In order to achieve this, I needed to modify the command by adding “newrelic-admin” in front of the command spawning gunicorn and passing config file setting as the environment variable.
version: "3.7"
services:
web:
image: "gonczor/aws-simple-app:prod"
env_file:
- .web.env
command: newrelic-admin run-program gunicorn wsgi:app -c ../configs/web/gunicorn_conf.py
working_dir: /app/src
volumes:
- ./configs/web/:/app/configs/web/
environment:
- NEW_RELIC_CONFIG_FILE=/app/configs/web/newrelic.ini
deploy:
placement:
constraints:
- node.labels.type == app
nginx:
image: "gonczor/aws-simple-app-nginx:prod"
ports:
- "80:80"
depends_on:
- web
volumes:
- ./configs/nginx/:/etc/nginx/conf.d/
deploy:
placement:
constraints:
- node.labels.type == app
Deploy constraints are a bit of an overkill since I only have one instance of docker machine running.
Testing
With Gitlab as my code repository provider, I wanted to make use of its CI/CD tools. The process I designed consisted of 2 stages:
- Test – whereby unit tests and linting were launched in 2 separate pipelines,
- Build – action conducted only on the master branch after the merge request was merged (merge request is equivalent to Github’s pull request). That’s where the building of the docker image and pushing it to the docker hub would take place.
I’ll only share the final configuration:
.before_scripts: &before_script
before_script:
- cp .web.env.example .web.env
- cp .db.env.example .db.env
- apk add python-dev py-pip libffi-dev openssl-dev gcc libc-dev make
- apk update
- pip install docker-compose
- docker-compose build
stages:
- test
- build
default:
image: docker
services:
- docker:dind
tests:
stage: test
services:
- docker:dind
- name: "postgres:11-alpine"
alias: db
script:
- docker-compose up -d db
- docker-compose up -d web
- docker-compose exec -T web python src/tests.py
<<: *before_script
lint:
stage: test
script:
- docker-compose up -d web
- docker-compose exec -T web flake8
<<: *before_script
build:
stage: build
script:
- docker login -u gonczor -p $DOCKER_HUB_ACCESS_TOKEN
- docker build -t gonczor/aws-simple-app:prod -f Docker/Dockerfile .
- docker push gonczor/aws-simple-app
only:
- master
Separating linting and unit tests has let me run stuff in a parallel manner. In larger projects, this would be a major advantage as it would result in streamlining the development process.
Once tests are passed and changes are merged, build is triggered for the master branch, image is pushed to my docker hub. I wanted to use a separate development branch but since I do not have any testing environment (I simply decided this is not necessary) I merge features directly into master. Token is stored as a variable in GitLab’s CI configuration so that it’s not revealed and I have easy access to it from CI setup. Once the image is pushed, I can pull it on the server and run the updated code version.
If I make a mistake and want to return to the last known good version, I only have to revert the merge request and deploy again, maybe reloading the database if changes are incompatible.
Joining the swarm
I created a single node deployment. Docker swarm allows adding servers on-demand using AWS and other cloud solutions, which means that I could launch my t2.micro instance from the local command line. Nonetheless, since I already had one server up and running I used a generic driver:
docker-machine create --driver generic --generic-ip-address=1.2.3.4 --generic-ssh-key ~/.ssh/id_rsa --generic-ssh-user=ubuntu srv1
Then, after logging in the machine via ssh, I needed to join nodes and deploy:
docker swarm init --advertise-addr 1.2.3.4
docker-swarm join-token manager
docker swarm join --token SOME_TOKEN 1.2.3.4:2377
docker stack deploy -c docker-compose.prod.yml demo
docker exec ec4cb96be20d python main.py createdb
With services up and running I could scale and monitor them.
docker service scale demo_web=2
demo_web scaled to 2
overall progress: 2 out of 2 tasks
1/2: running [==================================================>]
2/2: running [==================================================>]
verify: Service converged
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
9b6eoou4yoy0pcof2avamr7cl * srv1 Ready Active Leader 19.03.6
docker stack services demo
ID NAME MODE REPLICAS IMAGE PORTS
hs5z2f38zns3 demo_nginx replicated 1/1 gonczor/aws-simple-app-nginx:prod *:80->80/tcp
s1ezd24c2i5u demo_web replicated 2/2 gonczor/aws-simple-app:prod
Monitoring with Newrelic
As soon as I had everything up and running, I decided to run some load tests. That may not be the most exciting part for an application that has only 2 endpoints and performs 3 database queries (at the most) but I was curious how much traffic such a simple configuration can take. Remember: we are talking about Nginx and Gunicorn on the same free-tier server. It turned out that having scaled “web” service to 2 instances, I was able to handle 1 500 requests per minute.
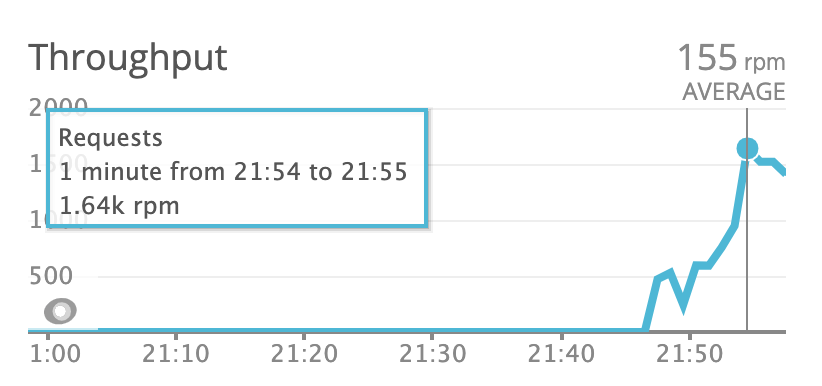
Newrelic also lets me monitor the slowest endpoints so that I know where to put my attention when trying to optimize the entire application.

Automating deployment with Ansible
The deployment process is extremely simple. All you do is
- pull changes from git,
- run “docker stack deploy -c docker-compose.prod.yml demo” command.
An additional step could be upgrading (or downgrading in case of reverting changes) the database schema, but this is currently not implemented.
Anyway, I wanted this automated. Ansible needed hosts file to know where it should run the commands:
demo.blacksheephacks.pl ansible_user=ubuntu
It also called for a “playbook”, which is a set of commands to be run on target hosts written in the form of yaml config:
- name: "Deploy docker stack"
hosts: all
tasks:
- name: "pull"
command:
chdir: aws-simple-app/
cmd: git pull
- name: "deploy"
command:
chdir: aws-simple-app/
cmd: docker stack deploy -c docker-compose.prod.yml demo
This, however, was still problematic since I wasn’t forwarding ssh keys needed to perform the “git pull”. To fix this, I needed to add the following lines in ~/.ansible.cfg:
[ssh_connection]
ssh_args=-o ForwardAgent=yes
This way I was able to successfully run my deploys with:
ansible-playbook -i ansible/hosts ansible/deploy.yml
Further improvements
In every project, there’s a possibility to do something better. Yet, I’m a fair believer in the claim that done is better than perfect so instead of introducing more and more minor changes ad mortem defaecatam, I decided to finally share with you what I’ve learned working on the project. However, if I were to continue my quest, I’d focus on the following enhancements:
- Creating a frontend
I was never that much interested in frontend work but I believe that putting some effort into it would not only cause the whole project to look nicer but also allow me to learn about stuff like serving static files (most probably, I’d go with S3 storage). Introducing some security mechanisms like CSP would also be a benefit.
- Using Kubernetes
I’ve seen what docker-swarm can do. I like it and I believe it’s enough for certain projects but I’m still curious what else can be achieved with Kubernetes. I also believe I could combine learning this tool and getting to know some other cloud solutions like GCP, which has free Kubernetes management tools (AWS has only paid options).
- Deploying on multiple nodes so that I could learn how to orchestrate more complex applications
- Improving the deployment process
I don’t need the entire codebase pulled, just docker-compose file and proper environment variables set. This would improve security since code wouldn’t be kept on the server but in docker images. Moreover, as I’ve already mentioned, it would be nice to have database upgrades and downgrades included.
Having said that, I need to stress out that working on this project, that I’ve learned a lot from an engineering perspective. One of the lessons was choosing proper tools before starting development. In this case, I was able to add more to the tech stack as I went on with the project and withdraw from certain decisions like the choice of database setup, which initially ran on the same server as the application inside a separate container and was moved to RDS later or changing docker-compose to docker swarm to run the project.
That’s it. I hope that you enjoyed the article and, ideally, found an inspiration to do something on your own.
Inspired to step up your coding game? Join us and work on ambitious projects daily!



Navigate the changing IT landscape
Some highlighted content that we want to draw attention to to link to our other resources. It usually contains a link .
.svg)
.svg)
.svg)
.avif)

.avif)
.avif)
.avif)